

Stemming vs. Lemmatization: What Healthcare Text Data Taught Me About NLP Choices
Introduction: When Words Become Data
When most people picture healthcare data, they think of numbers, rows and columns filled with blood pressure readings, cholesterol levels, BMI, age, lab test values, and hospital admissions. But hidden beneath those spreadsheets and charts is another goldmine of information: textual data. This comes in many forms, from doctors’ notes to discharge summaries, patient feedback, and even research papers, all of which contain insights that could transform patient care, if only we could analyse them effectively.

That’s where Natural Language Processing (NLP) steps in. Yet before any algorithm can uncover patterns in this text, we face a deceptively simple question: how should we represent words to machines? After all, machines don’t have the neurological or reasoning capacity that humans do. Do we chop words down to their rough stems, or carefully reduce them to linguistically valid forms through lemmatization?
To explore this trade-off, I ran a focused experiment comparing stemming and lemmatization on healthcare text data. What I discovered surprised me, and it changed the way I think about words, machines, and medicine
Why This Matters in Healthcare NLP
Healthcare language isn’t just messy, it’s life-altering. A single word can carry the weight of a diagnosis, shape a treatment plan, or even influence a patient’s future. With advances in technology, we have to be both careful and curious: are we sure that what we intend is exactly what gets passed to the machine? The old computing adage still holds true: garbage in, garbage out. And in healthcare, that principle isn’t theoretical, it can affect real human lives.
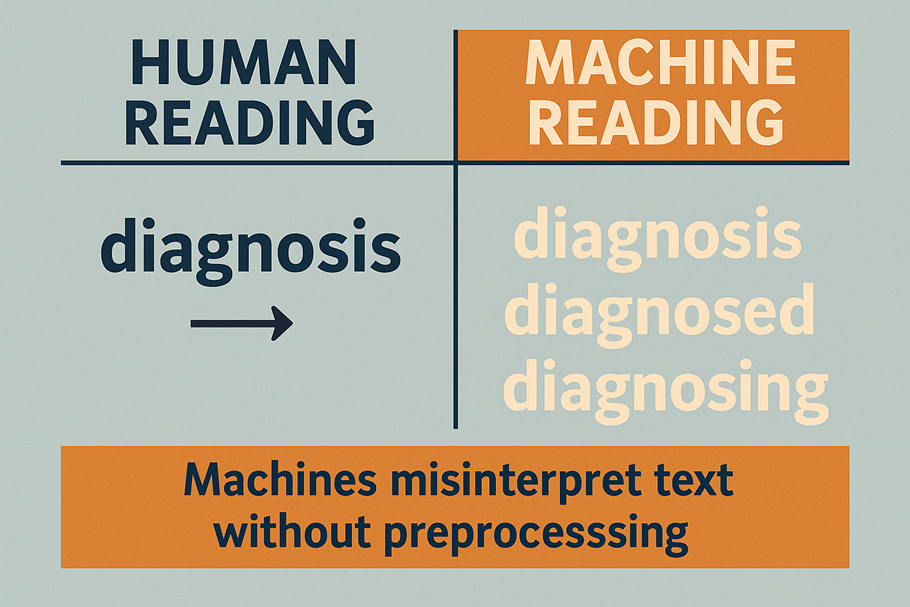
Think about it this way:
- “diagnosis” vs. “diagnosed” vs. “diagnosing”
- “tumor” vs. “tumorous”
- “medication” vs. “medicated”
To you and me, these words are obviously connected. But to a machine, they may as well belong to different universes. Without proper preprocessing, algorithms can stumble over these variations, misclassify records, or overlook critical patterns. And in healthcare, one misread word could be the difference between accurate insight and dangerous misinformation.
That’s why I wanted to put two of NLP’s most fundamental preprocessing techniques to the test:
- Stemming: quick, rule-based, and blunt, often leaving words looking like rough fragments.
- Lemmatization: slower, more resource-intensive, but grounded in linguistic accuracy and context.
The question driving me was simple but important: When applied to healthcare text, which one truly delivers, speed or accuracy?
The Experiment Setup
I wanted to strip this down to the essentials. No deep neural networks. No black-box transformers. Just pure, old-school preprocessing, the kind of foundation every NLP project rests on.
The Dataset
For the experiment, I pulled together a healthcare-related text dataset of about 9,653 words. It covered everything from preventive care and telemedicine to artificial intelligence in healthcare and mental health. In other words, a miniature version of the messy, varied language doctors, researchers, and patients use every day.
The Code
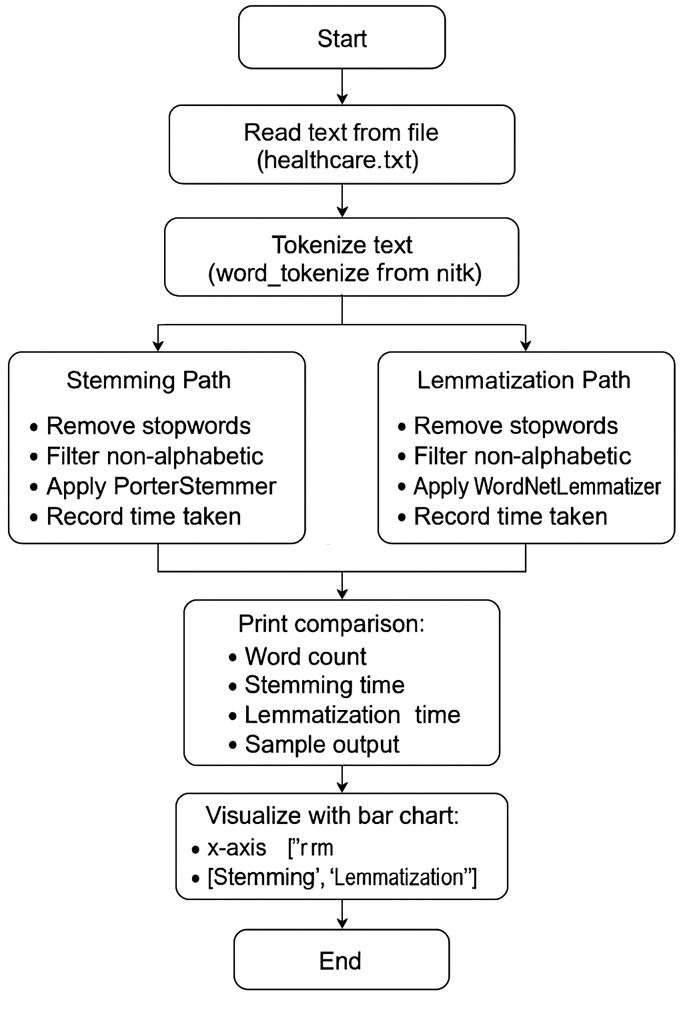
I built a lightweight preprocessing script in Python using NLTK. The steps were classic:
- Tokenization (breaking the text into words).
- Stopword removal (filtering out filler words like “the” and “is”).
- Stemming with PorterStemmer (fast, rule-based chopping of words).
- Lemmatization with WordNetLemmatizer (slower, but linguistically precise).
Once everything was in place, I compared both method on two simple but telling criteria: processing time it took both method on how quickly each approach runs or processes the data. And Interpretability of Medical Terms, basically checking how readable and medically accurate the results are.
Here’s a snippet from my setup, nothing fancy, just back-to-basics NLP:

Running this experiment felt almost like a throwback, reminding me that before we worry about sophisticated models, it’s the words themselves that need taming.
Results: Speed vs. Accuracy
When I finally pressed run, the stopwatch told one story, but the words told another. I ran the experiment 10 times on the same healthcare dataset to make sure the results weren’t a fluke. The outcome was consistent:
Stemming: between 0.04 and 0.07 seconds
Lemmatization: between 2.65 and 2.94 seconds
On the surface, stemming looked like the obvious winner, lightning fast, done almost before I could blink. Lemmatization, meanwhile, crawled in comparison, making me wait seconds longer for results. But here’s where the story shifts. Performance isn’t just about time. The technical foundations of each method remain the same, stemming is always heuristic and blunt, while lemmatization is always context-aware and linguistically precise. Better computing power might reduce processing times for lemmatization, but it won’t change the fact that its outputs are cleaner and more reliable. So while speed can fluctuate with dataset size and hardware, the real trade-off between quickness and clarity stays constant.
Bar Chart showing the difference in Processing Time
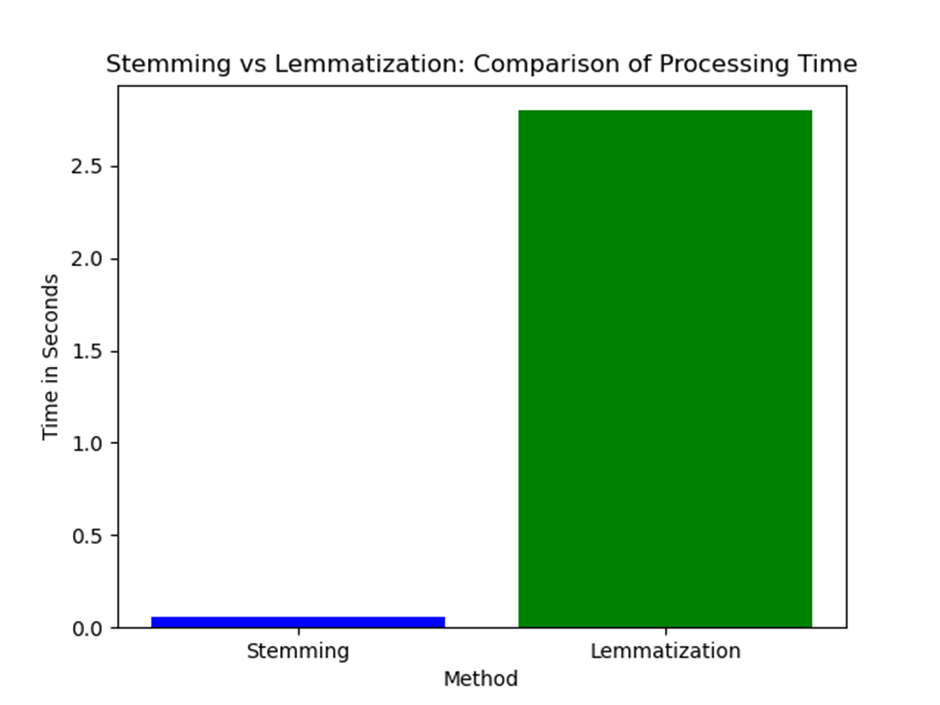
On paper, stemming looks like the obvious winner. It was lightning fast, done almost before I blinked. Lemmatization, on the other hand, crawled in comparison. By the time the results popped up, I could have scrolled Twitter or sipped some coffee.
But here’s the thing: speed is only half the story, so when I actually looked at the outputs, the picture shifted. Stemming chopped words into awkward, sometimes nonsensical fragments. I saw “diagnos” instead of diagnosis, “medicin” instead of medicine, “treat” instead of treatment. It felt like talking to someone who only half-finished their sentences. While Lemmatization on the other hand produced clean, dictionary-valid results: diagnosis, medicine, treatment. Slower, yes, but far more trustworthy.
In other words, stemming was quick but sloppy; lemmatization was deliberate but dependable. And in healthcare, where the meaning of a single word can shift an entire diagnosis, those differences aren’t cosmetic, they’re critical.
Key Insights
Looking back at the experiment, a few truths stood out, truths that go beyond just code and runtime.
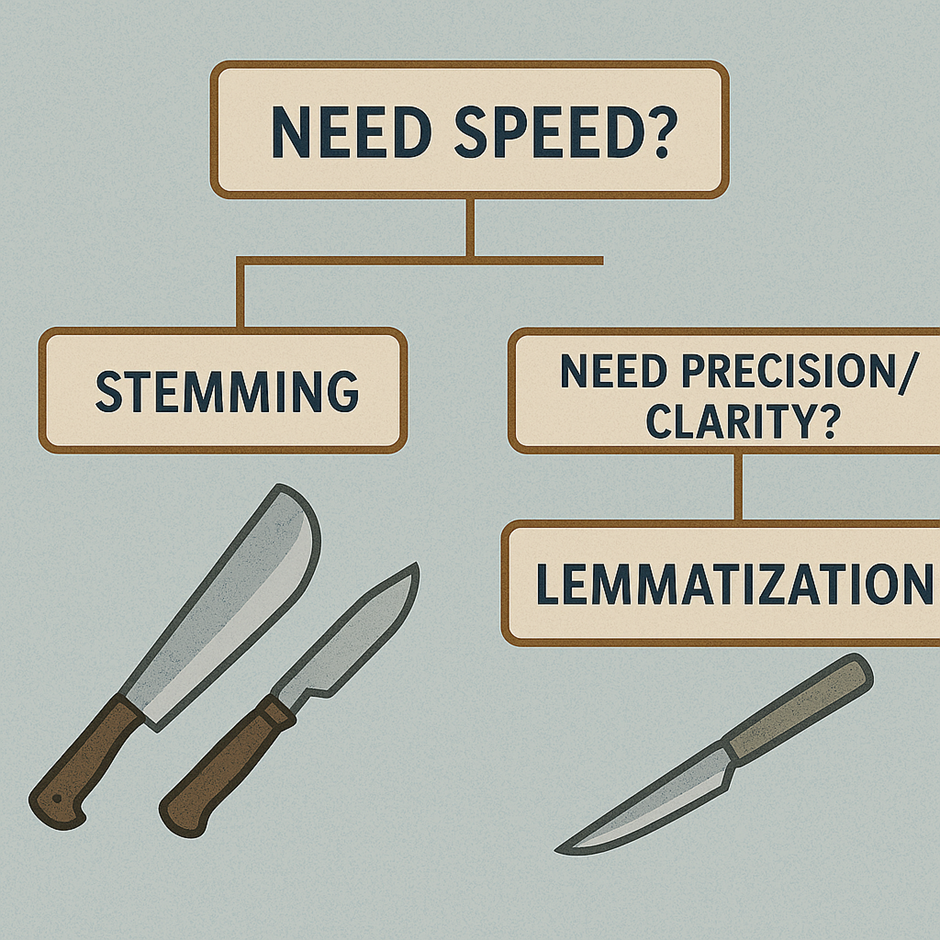
- Stemming is like a machete. It cuts through words fast, clearing the jungle of text in seconds. But it’s crude. Words are left half-finished, stripped down to fragments that don’t always make sense. If you’re processing millions of tweets or running a quick-and-dirty text mining job where small errors don’t matter, a machete might be all you need.
- Lemmatization is like a scalpel. It works slowly, carefully, taking into account grammar, context, and meaning. It won’t rush, but when it’s done, the results are precise and linguistically valid. In healthcare, where one misinterpreted word could shift a diagnosis or mislead a model, a scalpel is far more valuable than speed.
- The trade-off is real. This isn’t a case of “one is better, the other is useless.” The right choice depends on the context. If I were building a search engine for medical abstracts, stemming would be acceptable, it’s fast and the stakes are low. But if I were designing a predictive model for patient outcomes, I wouldn’t risk anything less than lemmatization. Accuracy and interpretability are non-negotiable when human health is on the line.
Challenges Along the Way
I’ll be honest, lemmatization tested my patience**.**
The first time I ran it; stemming was done before I could even glance at the console. Lemmatization, on the other hand, made me wait. Not forever, but long enough to feel the lag, two, sometimes three seconds for just under ten thousand words. It doesn’t sound like much, but when you’re running multiple trials, watching the clock tick, those seconds start to feel like an eternity.
Scaling that up to millions of medical notes or entire research databases? That’s when the slowness becomes a serious bottleneck. You’d need clever optimization, batching inputs, caching results, maybe even distributed processing, to make it practical.
But here’s the paradox: those delays forced me to confront the real question, what’s the cost of being fast but wrong?
In healthcare, accuracy isn’t a “nice-to-have.” It’s the difference between insight and misinformation, between a trusted system and one doctors ignore. I’d rather wait those extra seconds than risk misinterpreting patient data. The inconvenience reminded me of a core principle in data science: sometimes efficiency is less important than trust.
Looking Ahead
It’s tempting to think that with the rise of large language models, GPT, BERT, and their cousins, old-school preprocessing is a thing of the past. Just throw the raw text at a transformer and let it figure things out, right? I disagree. Why? Because not every healthcare setting looks like a Silicon Valley lab with racks of GPUs humming in the background. Many hospitals, especially in low-resource settings, still run on limited infrastructure. For them, classical NLP preprocessing is not just relevant, it’s essential. A simple, well-tuned pipeline with stemming or lemmatization can be the difference between having usable analytics and having nothing at all.
Even in high-resource settings, the basics still matter. Large models can produce powerful results, but they’re also black boxes. Without careful preprocessing, without knowing why words are being treated in certain ways, you risk building systems that are fast but untrustworthy. And trust is everything in healthcare.
That’s why my own focus is shifting toward blending the two worlds: the simplicity and reliability of classical NLP with the explainability of modern frameworks like SHAP. The future I see isn’t about choosing between stemming and lemmatization or discarding them entirely, it’s about using these building blocks to create models that are not only accurate, but also interpretable and fair.
Because at the end of the day, AI in healthcare isn’t just about what the machine can do, it’s about what doctors and patients can trust.
Conclusion: My Takeaway
This small experiment left me with a big realization: words matter more than we think.
If all you need is speed and you’re okay with a little messiness, stemming will get the job done. It’s quick, efficient, and perfect for scenarios where minor errors don’t carry much weight.
But if you care about clarity and correctness, especially in a field like healthcare, where a single word can change the meaning of an entire diagnosis, then lemmatization is the way forward. It’s slower, yes, but accuracy is worth the wait.
Because at the end of the day, healthcare isn’t just about crunching data points. It’s about human lives**.** And when lives are on the line, I’ll always choose accuracy over speed. For healthcare NLP, the choice is clear: lemmatization wins**.**
Future Work: Taking It Into the Real World

Of course, my experiment only scratched the surface. I worked with a curated healthcare-related text sample, but real clinical language is far messier. Think of doctors’ shorthand, cryptic acronyms, incomplete sentences, and the kind of medical jargon that only makes sense in context. That’s where datasets like MIMIC-IV or real electronic health records come in. Testing stemming and lemmatization on these richer, noisier datasets would reveal how well these techniques hold up under pressure. Beyond just speed and accuracy, future work should also explore how preprocessing choices influence explainability frameworks like SHAP or LIME when applied to life-critical healthcare models. That’s the next step I’m excited to tackle.
Note: Some images in this article were generated using AI tools for illustrative purposes.
I’ve open-sourced my code and results, feel free to check out the GitHub repo. \n If you’re working on NLP in healthcare, or just curious about how tiny preprocessing decisions can ripple into big consequences, connect with me on LinkedIn. I’d love to hear your stories, trade notes, and swap ideas.
You May Also Like

Young Republicans were more proud to be American under Obama than under Trump: data analyst

Vitalik Buterin Outlines Ethereum’s AI Framework, Pushes Back Against Solana’s Acceleration Thesis
